

Corpus
Il nostro corpus segue il modello proposto dalla metodologia del progetto AMPER, in particolare quella applicata al lavoro di Rodríquez et al. (2020), le cui frasi coincidono con il nostro corpus, eccetto per l'oggetto con l'accento sulla penultima posizione; mentre questi autori hanno utilizzato la parola “iaddina” (gallina), noi l'abbiamo sostituita con la parola “banana”. Tuttavia, il corpus è stato adattato foneticamente quando necessario. L'obiettivo di far coincidere, per quanto possibile, il nostro corpus con quello di altri studi basati sulla metodologia AMPER è di facilitare il futuro confronto dei nostri risultati con quelli di altri lavori, sia sul siciliano che su altre varietà. Le frasi di questo corpus seguono lo schema SVO, tutte hanno 11 sillabe e tre possibilità accentuali, sia per il soggetto che per il verbo, dando luogo a 9 combinazioni possibili tra proparossitone, parossitone e ossitone. La stessa frase è stata registrata in due modalità diverse: dichiarativa e interrogativa assoluta. Il risultato è un corpus di 18 frasi: 9 affermative e 9 interrogative assolute.
AFFERMATIVE |
INTERROGATIVE ABSOLUTE |
|
1. A fimmina manciava na fragula. 2. A fimmina manciava na banana. 3. A fimmina manciava nu baccalà. 4. U picciottu manciava na fragula. 5. U picciottu manciava na banana. 6. U picciottu manciava nu baccalà. 7. U vicirré manciava na fragula. 8. U vicirré manciava na banana. 9. U vicirré manciava nu baccalà. |
10. A fimmina manciava na fragula? 11. A fimmina manciava na banana? 12. A fimmina manciava nu baccalà? 13. U picciottu manciava na fragula? 14. U picciottu manciava na banana? 15. U picciottu manciava nu baccalà? 16. U vicirré manciava na fragula? 17. U vicirré manciava na banana? 18. U vicirré manciava nu baccalà? |
Punti di raccolta dati
Per quanto riguarda i punti di indagine, abbiamo tenuto in considerazione la classificazione in gruppi dialettali proposta da Piccitto (1950) con l'obiettivo di coprire tutte le aree descritte dall'autore. Inoltre, abbiamo preso in considerazione i risultati dei lavori di Grice (1995), Gili Fivela e Iraci (2017), Rodríguez et al. (2020) e De Iacovo (2019) per valutare l'interesse di ciascun punto di indagine, offrire risultati di diverse varietà e raccogliere campioni nelle stesse località, permettendoci così di confrontare il nostro materiale. Inoltre, abbiamo realizzato un breve questionario a parlanti nativi siciliani in cui chiedevamo se trovassero simile o diversa l'intonazione delle parlate delle località a loro vicine. Abbiamo deciso di concentrare la nostra analisi sui punti di indagine urbani, almeno nella loro grande maggioranza, cercando inoltre che la distanza tra di essi fosse equilibrata e tenendo conto del criterio dello stesso ricercatore nella valutazione dell'interesse delle registrazioni. Come risultato, siamo riusciti a ottenere campioni da Agrigento, Alcamo, Caltagirone, Caltanissetta, Canicattì, Castelbuono, Catania, Corleone, Enna, Lentini, Marsala, Mazara del Vallo, Modica, Palermo, Paternò, Piana degli Albanesi, Sciacca, Serradifaco, Siracusa, Termini Imerese e Trapani, per un totale di 21 località.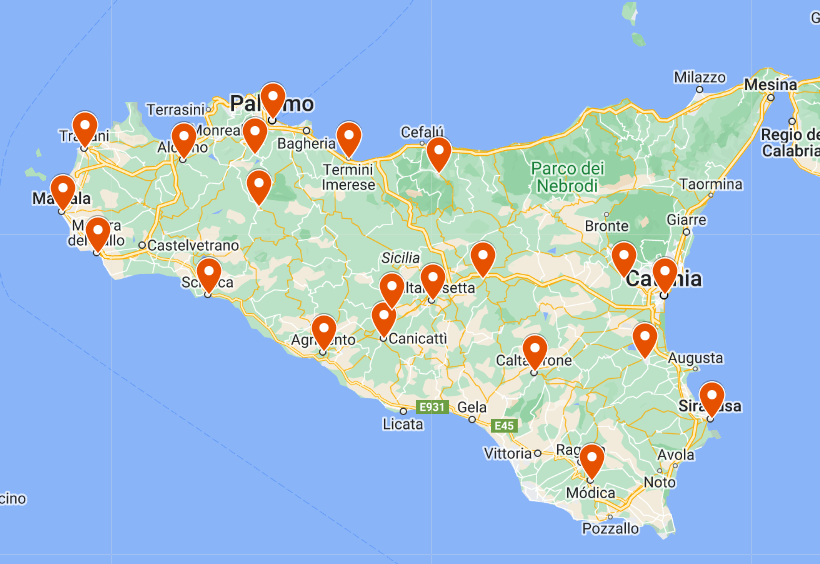 Ci sarebbe piaciuto coprire la provincia di Messina o alcuni punti del sud dell'isola come Licata e Gela, ma abbiamo dovuto fermare la raccolta dei campioni per ragioni di estensione e di tempo. Tuttavia, speriamo di continuare il progetto e ampliarlo con nuovi punti di raccolta dati , informatori e modalità frasali.
Ci sarebbe piaciuto coprire la provincia di Messina o alcuni punti del sud dell'isola come Licata e Gela, ma abbiamo dovuto fermare la raccolta dei campioni per ragioni di estensione e di tempo. Tuttavia, speriamo di continuare il progetto e ampliarlo con nuovi punti di raccolta dati , informatori e modalità frasali.
Informatori
Per quanto riguarda gli informatori, non è stato difficile trovare parlanti di dialetto, ma lo è stato trovare locutori in grado di parlare con naturalità utilizzando un corpus letto. A tal fine, è stata fondamentale l'intervista preliminare, il cui obiettivo era scartare quegli informatori che non fossero in grado di leggere le frasi in modo neutro o che avessero patologie del linguaggio, selezionando invece quelli che fossero spontanei e rappresentativi della loro varietà dialettale. Abbiamo cercato di restringere il gruppo campione a soggetti della seconda o terza generazione, uomini e donne di età superiore ai 45 anni, nativi del comune in questione e che avessero vissuto la maggior parte della loro vita in quella località. Inoltre, abbiamo compilato una scheda di controllo per ogni locutore con informazioni rilevanti che ci potessero aiutare a valutare la sua intonazione: punto di indagine, etichetta dell'informatore, luogo di nascita, residenza abituale, luoghi in cui ha vissuto, età, formazione e contesto di utilizzo del dialetto. Nonostante avessimo stabilito questi requisiti, non sempre siamo riusciti ad ottenere campioni da un uomo e una donna per ogni punto di indagine, e abbiamo anche deciso di includere alcuni informatori sotto i 45 anni, poiché già avevamo la loro partecipazione e li abbiamo ritenuti rappresentativi del loro dialetto.Raccolta dei campioni
Le registrazioni sono state effettuate in due modalità: in presenza e online. Il fatto di aver elaborato un metodo per la raccolta dei campioni a distanza ci ha permesso di raggiungere più punti di indagine con le risorse di cui disponevamo e di registrare in momenti di silenzio nelle stanze degli informatori. Siamo riusciti a contattarli tramite i social media o grazie a contatti comuni, e abbiamo fornito loro istruzioni semplici. Il risultato delle registrazioni a distanza è stato un successo, senza riscontrare difficoltà maggiori rispetto alle registrazioni in presenza. Tutti gli informatori hanno registrato il corpus in siciliano almeno 4 volte, e abbiamo selezionato solo le 3 migliori per il nostro studio.Etichettatura
Il sistema di etichettatura del materiale segue le indicazioni della metodologia AMPER, che ci consente di conoscere le informazioni su ogni audio attraverso un sistema di codici che indica la località di provenienza, la lingua, il sesso, la struttura sintattica della frase, la modalità della stessa —cioè, se affermativa o interrogativa— e il numero di ripetizione della frase.| 1 | Località | Sesso2 |
| 8p02 | Agrigento | Uomo |
| 8p12 | Alcamo | Uomo |
| 8p11 | Alcamo | Donna |
| 8p22 | Caltagirone | Uomo |
| 8p21 | Caltagirone | Donna |
| 8o44 | Caltanissetta | Uomo |
| 8o43 | Caltanissetta | Donna |
| 8p32 | Canicattì | Uomo |
| 8p31 | Canicattì | Donna |
| 8p42 | Castelbuono | Uomo |
| 8p41 | Castelbuono | Donna |
| 8o73 | Catania | Uomo |
| 8p52 | Corleone | Uomo |
| 8p62 | Enna | Uomo |
| 8p71 | Lentini | Donna |
| 8p81 | Marsala | Uomo |
| 8p92 | Mazara del Vallo | Uomo |
| 8p91 | Mazara del Vallo | Donna |
| 8q02 | Modica | Uomo |
| 8q01 | Modica | Donna |
| 8o04 | Palermo | Uomo |
| 8o03 | Palermo | Donna |
| 8q12 | Paternò | Uomo |
| 8q22 | Piana degli Albanesi | Uomo |
| 8q21 | Piana degli Albanesi | Donna |
| 8q32 | Sciacca | Uomo |
| 8q31 | Sciacca | Donna |
| 8q41 | Serradifalco | Donna |
| 8q52 | Siracusa | Uomo |
| 8o24 | Termini Imerese | Uomo |
| 8o21 | Termini Imerese | Donna |
| 8o14 | Trapani | Uomo |
| SOGGETTO | VERBO | OGGETTO | |
| Kwk | U vicirrè | manciava | nu baccalà. |
| Kwp | na fragula. | ||
| Kwt | na banana. | ||
| Pwk | A fimmina | nu baccalà. | |
| Pwp | na fragula. | ||
| Pwt | na banana. | ||
| Twk | U picciottu | nu baccalà. | |
| Twp | na fragula. | ||
| Twt | na banana. |
| 8p4 | 2 | pwp |
| Località - lingua | sesso | Struttura sintattica |
| I | 2 |
| Modalità frasale | ripetizione |