

Corpus
Nuestro corpus sigue el modelo propuesto por la metodología del proyecto AMPER, en particular, aquella aplicada al trabajo de Rodríquez et al. (2020), cuyas frases coinciden con nuestro corpus excepto en el objeto con el acento en penúltima posición; mientras estos autores utilizaron la palabra “iaddina” (gallina), nosotros la sustituimos por la palabra “banana”. Aun así, el corpus fue adaptado fonéticamente cuando era pertinente. El objetivo de hacer coincidir, en la medida de lo posible, nuestro corpus con el de otros estudios basados en la metodología AMPER es facilitar la futura comparación de nuestros resultados con los de otros trabajos, tanto sobre el siciliano como sobre otras variedades. Las frases de este corpus responden al esquema SVO, todas ellas tienen 11 sílabas y tres posibilidades acentuales, tanto para el sujeto como para el verbo, dando lugar a 9 combinaciones posibles entre proparoxítonas, paroxítonas y oxítonas. La misma frase ha sido grabada en dos modalidades distintas: declarativa e interrogativa absoluta. El resultado es un corpus de 18 frases: 9 afirmativas y 9 interrogativas absolutas.
AFIRMATIVAS |
INTERROGATIVAS ABSOLUTAS |
|
1. A fimmina manciava na fragula. 2. A fimmina manciava na banana. 3. A fimmina manciava nu baccalà. 4. U picciottu manciava na fragula. 5. U picciottu manciava na banana. 6. U picciottu manciava nu baccalà. 7. U vicirré manciava na fragula. 8. U vicirré manciava na banana. 9. U vicirré manciava nu baccalà. |
10. A fimmina manciava na fragula? 11. A fimmina manciava na banana? 12. A fimmina manciava nu baccalà? 13. U picciottu manciava na fragula? 14. U picciottu manciava na banana? 15. U picciottu manciava nu baccalà? 16. U vicirré manciava na fragula? 17. U vicirré manciava na banana? 18. U vicirré manciava nu baccalà? |
Puntos de encuesta
En cuanto a los puntos de encuesta, tuvimos en cuenta la clasificación en grupos dialectales de Piccitto (1950) con el objetivo de cubrir todas las áreas descritas por el autor. Por otro lado, tomamos en consideración los resultados de los trabajos de Grice (1995), Gili Fivela e Iraci (2017), Rodríguez et al. (2020) y De Iacovo (2019) para evaluar el interés de cada punto de encuesta, ofrecer resultados de diferentes variedades y recoger muestras en las mismas localidades, permitiéndonos así comparar nuestro material. Además, realizamos un breve cuestionario a nativos sicilianos en el que les preguntábamos si encontraban similar o diversa la entonación de las hablas de las localidades cercanas a ellos. Decidimos centrar nuestro análisis en los puntos de encuesta urbanos, al menos en su gran mayoría, intentando, además, que la distancia entre ellos fuera equilibrada y teniendo en cuenta el propio criterio del investigador a la hora de valorar el interés de las grabaciones. Como resultado, conseguimos obtener muestras de Agrigento, Alcamo, Caltagirone, Caltannissetta, Canicattì, Castelbuono, Catania, Corleone, Enna, Lentini, Marsala, Mazara del Vallo, Modica, Palermo, Paternò, Piana degli Albanesi, Sciacca, Serradifaco, Siracusa, Termini Imerese y Trapani, 21 localidades en total.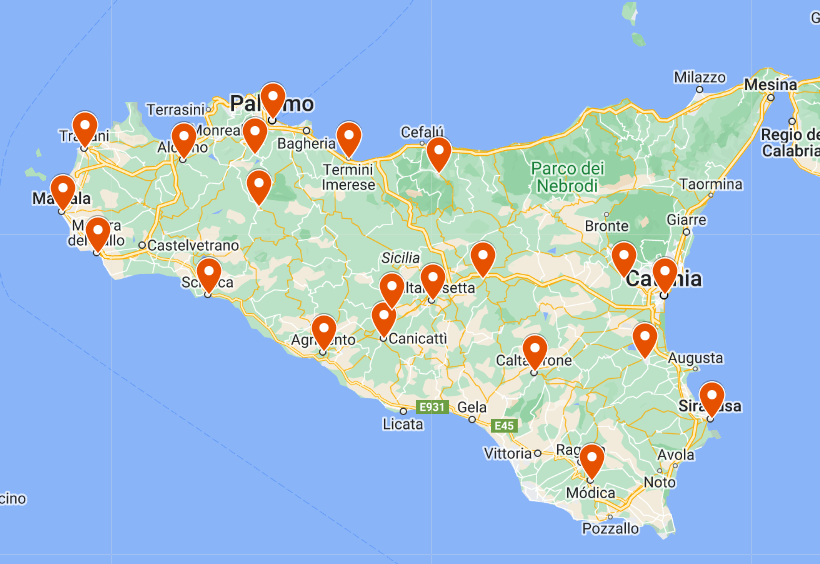 Nos hubiera gustado cubrir la provincia de Messina o algunos puntos del sur de la isla como Licata y Gela, pero tuvimos que detener la recogida de muestras por razones de extensión y de tiempo. Aun así, esperamos continuar con el proyecto y ampliarlo con nuevos puntos de encuesta, informantes y modalidades oracionales.
Nos hubiera gustado cubrir la provincia de Messina o algunos puntos del sur de la isla como Licata y Gela, pero tuvimos que detener la recogida de muestras por razones de extensión y de tiempo. Aun así, esperamos continuar con el proyecto y ampliarlo con nuevos puntos de encuesta, informantes y modalidades oracionales.
Informantes
Con respecto a los informantes, no fue un reto encontrar hablantes de dialecto, pero sí locutores que consiguieran hablarlo con naturalidad utilizando un corpus leído. Para ello fue fundamental la entrevista previa, cuyo objetivo era descartar aquellos informantes que no fuesen capaces de leer las frases de forma neutra o que tuvieran patologías del habla y, por el contrario, seleccionar a aquellos que fuesen espontáneos y constituyeran una muestra representativa de su variedad dialectal. Intentamos acotar el grupo de muestra a sujetos de la segunda o tercera generación, hombre y mujer de más de 45 años, oriundos del municipio en cuestión y que hayan residido la mayor parte de su vida en esa localidad. Además, rellenamos una ficha de control sobre cada locutor con información relevante que nos podría ayudar a la hora de valorar su entonación: punto de encuesta, etiqueta del informante, lugar de nacimiento, residencia habitual, lugares en los que ha residido, edad, formación y contexto de uso del dialecto. A pesar de habernos propuesto estos requisitos, no siempre pudimos obtener muestras de un hombre y una mujer para todos los puntos de encuesta y también decidimos incluir a algunos informantes menores de 45 años puesto que ya contábamos con su participación y consideramos que sí eran una muestra representativa de su dialecto.Recogida de muestras
Las grabaciones fueron realizadas a través de dos modalidades: presencial y en línea. El hecho de elaborar un método para la recogida de muestras a distancia nos permitió llegar a más puntos de encuesta con los recursos de los que disponíamos y conseguir grabar en momentos de silencio desde la habitación de los informantes. Pudimos contactar con ellos a través de las redes sociales o gracias a contactos en común y les facilitamos instrucciones sencillas. El resultado de las grabaciones a distancia fue un éxito, no se encontraron más dificultades que en las grabaciones de forma presencial. Todos los informantes grabaron el corpus en siciliano al menos 4 veces, de las que seleccionamos solo las 3 mejores para nuestro estudio.Etiquetaje
El sistema de etiquetaje del material sigue las instrucciones de la metodología AMPER, que nos permite conocer la información de cada audio con un sistema de códigos que indican la localidad de proveniencia y la lengua, el sexo, la estructura sintáctica de la frase, la modalidad de esta —esto es, si es afirmativa o interrogativa— y el número de repetición de la frase.| 1 | Localidad | Sexo2 |
| 8p02 | Agrigento | Hombre |
| 8p12 | Alcamo | Hombre |
| 8p11 | Alcamo | Mujer |
| 8p22 | Caltagirone | Hombre |
| 8p21 | Caltagirone | Mujer |
| 8o44 | Caltanissetta | Hombre |
| 8o43 | Caltanissetta | Mujer |
| 8p32 | Canicattì | Hombre |
| 8p31 | Canicattì | Mujer |
| 8p42 | Castelbuono | Hombre |
| 8p41 | Castelbuono | Mujer |
| 8o73 | Catania | Hombre |
| 8p52 | Corleone | Hombre |
| 8p62 | Enna | Hombre |
| 8p71 | Lentini | Mujer |
| 8p81 | Marsala | Hombre |
| 8p92 | Mazara del Vallo | Hombre |
| 8p91 | Mazara del Vallo | Mujer |
| 8q02 | Modica | Hombre |
| 8q01 | Modica | Mujer |
| 8o04 | Palermo | Hombre |
| 8o03 | Palermo | Mujer |
| 8q12 | Paternò | Hombre |
| 8q22 | Piana degli Albanesi | Hombre |
| 8q21 | Piana degli Albanesi | Mujer |
| 8q32 | Sciacca | Hombre |
| 8q31 | Sciacca | Mujer |
| 8q41 | Serradifalco | Mujer |
| 8q52 | Siracusa | Hombre |
| 8o24 | Termini Imerese | Hombre |
| 8o21 | Termini Imerese | Mujer |
| 8o14 | Trapani | Hombre |
| SUJETO | VERBO | OBJETO | |
| Kwk | U vicirrè | manciava | nu baccalà. |
| Kwp | na fragula. | ||
| Kwt | na banana. | ||
| Pwk | A fimmina | nu baccalà. | |
| Pwp | na fragula. | ||
| Pwt | na banana. | ||
| Twk | U picciottu | nu baccalà. | |
| Twp | na fragula. | ||
| Twt | na banana. |
| 8p4 | 2 | pwp |
| Localidad-lengua | sexo | Estructura sintáctica |
| i | 2 |
| Modalidad oracional | repetición |